Refereed Conference Proceedings
Publications by year. * indicates that authors contributed equally.
2024


CLaC at SemEval-2024 Task 2: Faithful Clinical Trial Inference
Jennifer Marks, MohammadReza Davari, and Leila Kosseim (SemEval 2024)

Scalable Upcycling of Finetuned Foundation Models via Sparse Task Vectors Merging
MohammadReza Davari and Eugene Belilovsky (ICML 2024 Workshop FM-Wild)
2023


2022

Deceiving the CKA Similarity Measure in Deep Learning
MohammadReza Davari*, Stefan Horoi*, Amine Natik, Guillaume Lajoie, Guy Wolf and Eugene Belilovsky (NeurIPS ML Safety Workshop 2022)
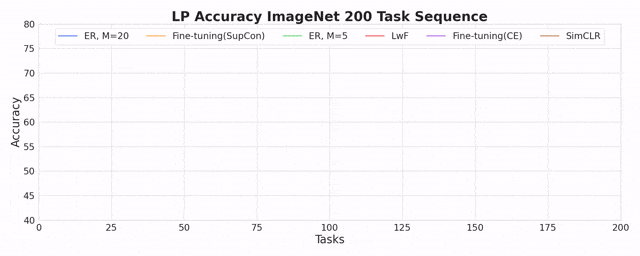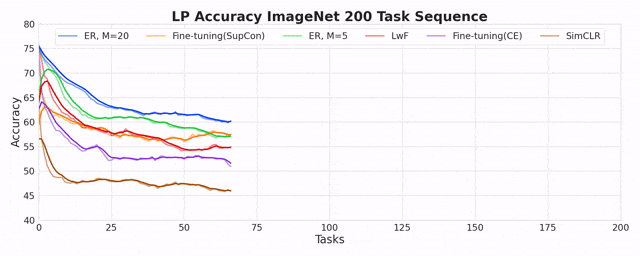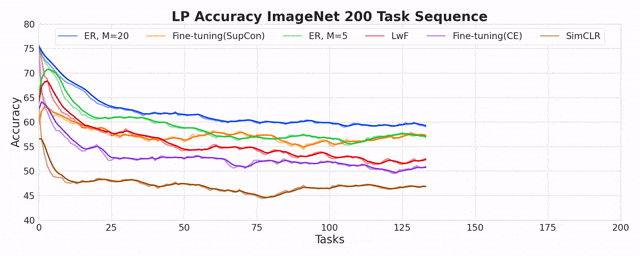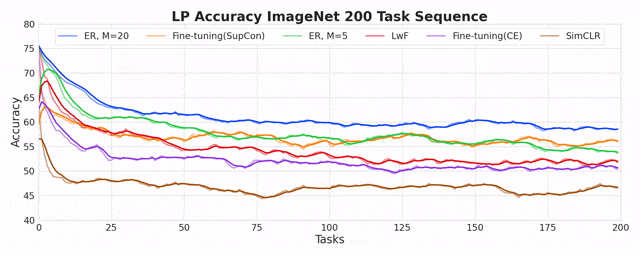

On the Inadequacy of CKA as a Measure of Similarity in Deep Learning
MohammadReza Davari*, Stefan Horoi*, Amine Natik, Guillaume Lajoie, Guy Wolf and Eugene Belilovsky (ICLR GTRL Workshop 2022)
2021
Probing Representation Forgetting in Continual Learning
MohammadReza Davari and Eugene Belilovsky (NeurIPS DistShift Workshop 2021)

Semantic Similarity Matching Using Contextualized Representations
Farhood Farahnak, Elham Mohammadi*, MohammadReza Davari*, and Leila Kosseim (CanAI 2021)
2020
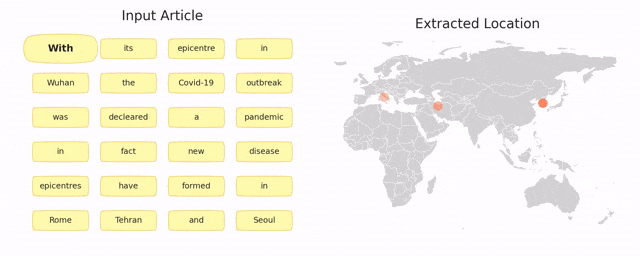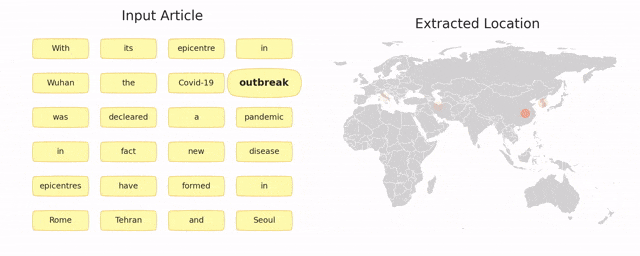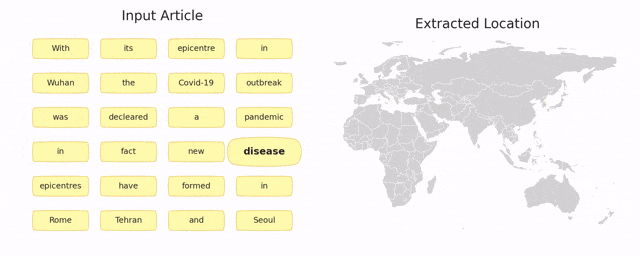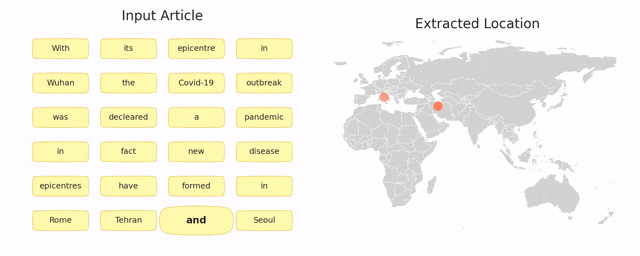
TIMBERT: Toponym Identifier For The Medical Domain Based on BERT
MohammdReza Davari, Leila Kosseim and Tien Bui (COLING 2020)
2019
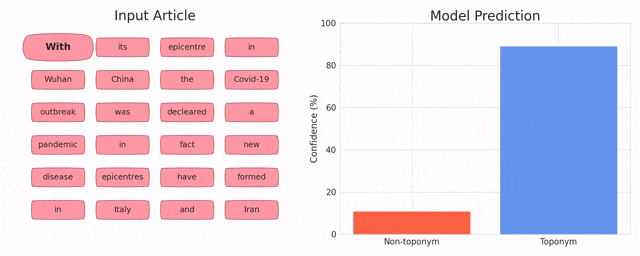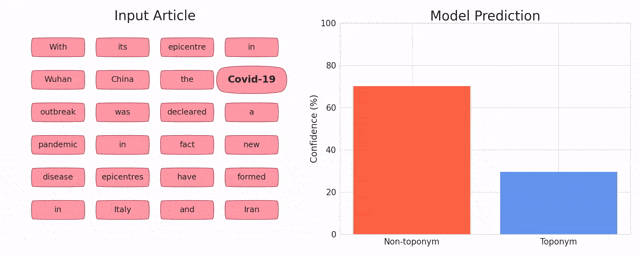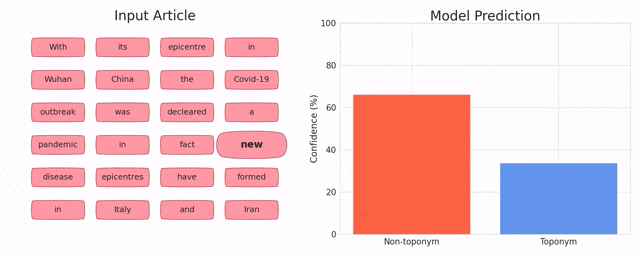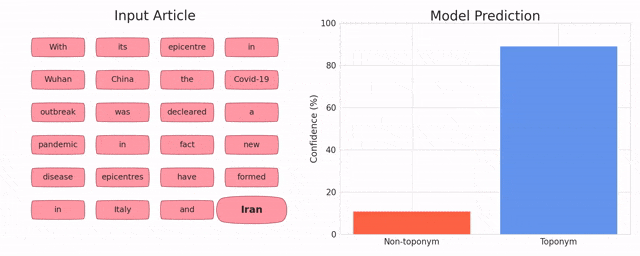
Toponym Identification in Epidemiology Articles - A Deep Learning Approach
MohammdReza Davari, Leila Kosseim and Tien Bui (CICLing 2019)
Best Poster Award